
Ces dernières années, les entreprises détentrices des réseaux sociaux numériques (comme Google, Facebook, Twitter ou ByteDance, l’entreprise détentrice du réseau social TikTok) ont beaucoup investi dans le recours à l’IA et à l’apprentissage automatique pour décupler leurs capacités de repérage et de modération des contenus illicites sur le web. La montée de la haine en ligne ou encore l’emballement médiatique autour des fake news ont instauré un climat médiatique parfois hostile aux contenus diffusés sur les réseaux sociaux et une panique morale pour réguler le web à tout prix. Entre bras de fer législatifs et marronniers médiatiques, la manière de modérer les réseaux sociaux numériques est passée d’un questionnement technique opéré à huis clos par les entreprises à un enjeu éminemment politico-publique.
Toutefois en parallèle de ce recours plus massif à l’IA, certaines communautés en ligne disent avoir fait l’objet d’une vague de censure abusive de la part des plates-formes. Comment le recours à l’IA dans la modération des réseaux sociaux engendre-t-il des discriminations à l’encontre de certaines catégories protégées ?
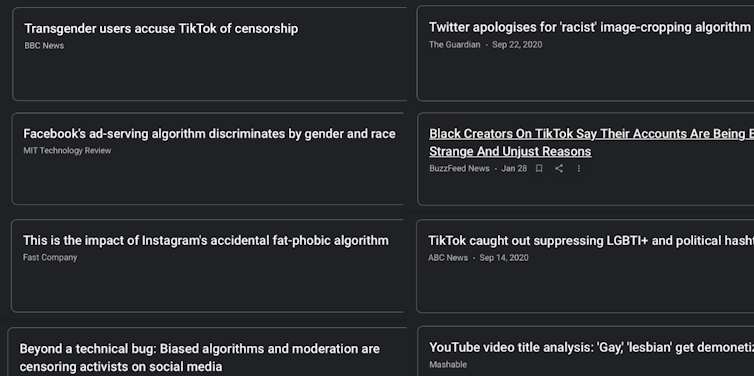
Lutter contre la prolifération des contenus illicites en ligne, mais à quel prix ?
Aujourd’hui, nul ne sait vraiment comment la haine en ligne est concrètement modérée sur les réseaux sociaux numériques.
On sait que des entreprises comme Facebook et Twitter emploient des modérateurs dans des sociétés de sous-traitance à l’étranger dans des conditions de travail parfois douteuses, mais aussi qu’elles possèdent leurs propres équipes de modérateurs pour gérer les contenus illicites et le référencement des publications en interne, et enfin qu’une partie de cette modération est de plus en plus déléguée à des algorithmes de machine learning, chargés de « nettoyer » les plates-formes de tous les contenus qu’elles auront jugé indésirables conformément aux règles fixées par les chartes et conditions d’utilisation des plates-formes.
Le travail de modération sur les réseaux sociaux numériques est donc à la fois réalisé par des humains et de manière automatisée, sans que l’on connaisse avec certitude les modalités d’articulation de ces méthodes, ainsi que la part de contenus traités exclusivement de manière automatique.
Or la délégation du travail de modération à l’IA semble aller de pair avec la discrimination à l’encontre des minorités sexuelles, de genre et de race. En effet ces dernières années, de nombreux utilisateurs ont tenté d’alerter les entreprises au sujet des injustices dont ils étaient victimes sur leurs plates-formes respectives. Ces injustices pouvaient prendre les formes suivantes : suppressions de comptes, censure automatique de posts, démonétisation de vidéos ou encore dé-référencement de contenus, via le phénomène de shadowban.

Les formes de censure sont donc multiples et divergent d’un réseau social numérique à l’autre.
De nombreux exemples de discriminations liées à la modération en ligne
Prenons l’exemple des utilisateurs et utilisatrices ouvertement LGBT+ pour illustrer notre point. En 2019, le mouvement « SEO Lesbienne » avait tenté de créer un compte Facebook comportant le mot « lesbienne », en vain. Ce nom d’utilisateur était automatiquement refusé par la plate-forme pour le motif suivant : « Il comporte des mots qui ne sont pas autorisés sur Facebook ».
Plus récemment sur Facebook et Twitter, des comptes de militants LGBT ont été temporairement suspendus en raison de la mention de leur orientation sexuelle dans leur bio (Twitter) ou descriptions de leur photo de profil (Facebook) : l’IA assimilait la mention de mots-clés comme « pédé » ou « gouine » a du contenu nécessairement haineux sans prendre en compte le contexte d’énonciation et la réappropriation militante de ces termes.
Sur TikTok, une étude menée par le think tank australien ASPI (Australian Strategic Policy Institute) a montré que selon la langue utilisée par l’utilisateur des réseaux sociaux numériques, certains hashtags LGBT+ étaient déréférencés de la plate-forme. Citons-en quelques exemples : يسنج لوحتملا# soit « transgenre » en arabe, #ягей pour « je suis gay » en russe, #Intersex pour « intersexe » en anglais ou encore #gej pour « gay » en bosnien et estonien. Ces quelques exemples constituent une des facettes de ce à quoi peut ressembler la discrimination algorithmique dans la modération des réseaux sociaux numériques.
On appellera discrimination algorithmique toute discrimination causée par un recours aux algorithmes. Il s’agit, en d’autres termes, de l’expérience de la discrimination vécue par les utilisateurs de ces services automatisés. Mais quelle en est la cause ?
A l’origine, les biais algorithmiques
La discrimination algorithmique résulte de l’introduction de « biais » au moment de la conception des algorithmes. Ces biais consistent en la transposition d’observations générales (souvent stéréotypées) ou statistiques en conditions algorithmiques systématiques. Il en existe plusieurs types et ils peuvent apparaître à différents moments du cycle de vie d’un algorithme. Je propose de les réunir en trois grandes catégories.
La première relève de la qualité des données d’apprentissage des algorithmes de machine learning. Dans leur écrasante majorité, ces données contiennent déjà des biais discriminants, que les algorithmes vont ensuite reproduire de façon « mécanique ». Par exemple, les algorithmes entraînés à partir de corpus moissonnés sur le web peuvent finir par associer le mot « lesbienne » à des contenus pornographiques et donc à considérer des contenus militants comme problématiques.
La seconde catégorie de biais porte sur ce qu’on appelle tantôt « biais de société », « biais cognitifs » ou encore « biais de stéréotypes » selon les langues et champs de recherche en IA. Il s’agit des représentations biaisées et des impensés des concepteurs (humains) transférés aux machines au moment de la conception.
Enfin, les objectifs de rentabilité et des critères garantissant l’efficacité d’un algorithme peuvent aussi engendrer des biais algorithmiques. Selon l’importance qu’on donnera à un critère (souvent financier) plus qu’à un autre, les algorithmes, pour répondre à cet objectif qui constitue leur raison d’être, pourront engendrer des discriminations collatérales. En guise d’exemple, imaginons un algorithme de recommandation dont la mission principale serait de promouvoir les contenus qui génèrent le plus de trafic en ligne (et donc de revenus pour les entreprises comme Google).
Le mot « lesbienne » renvoyant essentiellement à du contenu pornographique destiné à un public hétérosexuel et masculin ; les algorithmes de recommandation mettront en avant ce type de contenus (parce que reconnu comme populaire) dans les résultats de recherche. La pertinence des résultats de recherche ne coïncide donc pas avec les enjeux de représentation et de visibilisation des différentes orientations sexuelles et identités de genre en ligne, qui n’ont tout simplement pas été pris en compte par les concepteurs. On appellera cette négligence un « biais de variable omise ».
Trop souvent perçus comme neutres et objectifs, les algorithmes (comme toute technologie) peuvent, selon les usages et les concepteurs qui les mettent en service, reproduire des injustices déjà existantes dans la société.
La question qui se pose à présent est celle de la responsabilité. Si des titres de presse comme « L’algorithme anti-haine de Google est raciste envers les noirs » ou « TikTok’s algorithm is promoting homophobia » semblent caricaturaux aux yeux des défenseurs de l’IA qui jugent absurde le fait d’imputer la responsabilité de la discrimination aux algorithmes et à leurs concepteurs, le problème de la discrimination demeure.
Pourtant, dès lors que les cas de censure en ligne se multiplient et que ces outils sont toujours déployés, il appartient aux communautés scientifiques et militantes de mettre au jour les effets de ces outils sur les populations et la responsabilité des entreprises à maintenir leur mise en service alors même qu’ils contribuent à la (re)production d’injustices.
De plus, le désir de légiférer contre la haine en ligne ou les fake news ne saurait se faire sans un contrôle des outils automatiques de modération, au risque d’accroître les cas de discriminations algorithmiques. En effet, le projet de loi visant à lutter contre les contenus haineux en ligne portée par la députée LREM Laëtitia Avia a fait craindre un recours plus accru aux algorithmes en raison du nouveau délai de 24 heures imposé aux plates-formes pour supprimer les contenus qu’elles auraient jugé illicites. Plutôt que de proposer une loi pour lutter contre la haine en ligne qui risquerait d’avoir de lourdes conséquences sur la liberté d’expression des personnes que la loi vise à protéger, il conviendrait d’abord de réduire l’impact discriminant du recours aux algorithmes dans les réseaux sociaux en pénalisant les détenteurs des plates-formes lorsqu’ils discriminent des populations.
Les algorithmes interviennent de plus en plus dans nos vies quotidiennes et affectent la manière dont nous recevons l’information et percevons le monde – pensons à réguler la manière dont ils nous régulent, avant de leur donner plus de pouvoir.
Thibault Grison, Doctorant en Sciences de l’Information et de la Communication, Sorbonne Université
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.